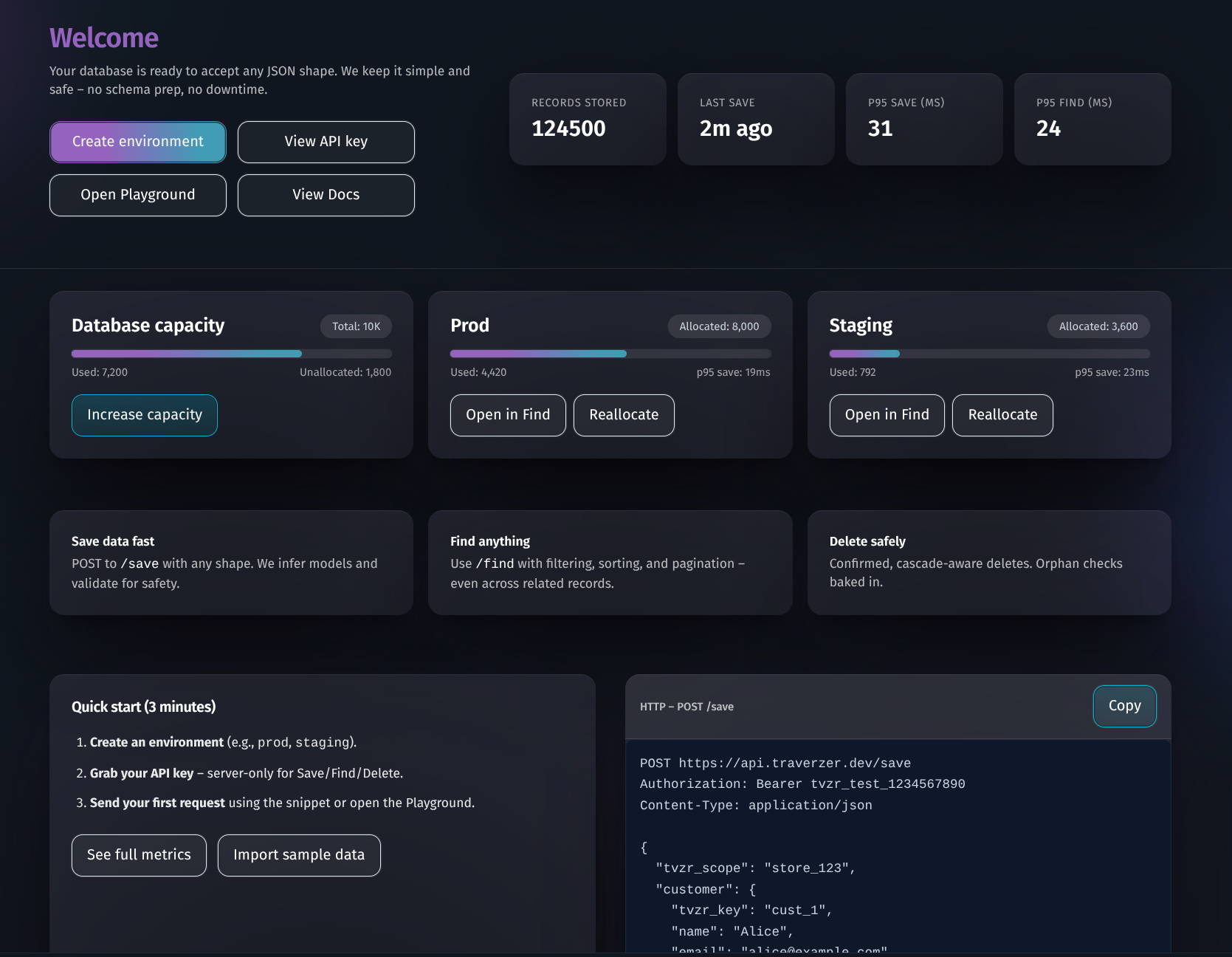
Make data simple. Schema-last, safety-first.
Traverzer stores and manages your data with a simple API, strong guardrails, and a developer experience that stays out of your way. Schema changes happen safely in the background while your data keeps flowing — so your team can move forward with confidence.
Why Traverzer
Your data's schema shouldn't require a committee.
Define the schema when you know it, not before.
Schema-last
Traverzer supports schema-on-ingest — automatically learning structure from the data you send. But when you need more control, you can also define schema directly via the API. Both approaches work side by side, so you can start flexible and tighten later. Either way, your schema evolves safely, with no brittle migrations or downtime.
Safety-first
Traverzer is built so your database stays healthy even while the schema evolves. You can add, rename, or retire fields and models without risking downtime or broken migrations. Either way, schema changes are reconciled automatically, so production queries keep working while the structure shifts.
Minimal APIs
Traverzer keeps the surface area small: one endpoint with verbs for saving, finding, updating, and deleting data, plus a slim REST-style path for schema actions. That’s it. Fewer moving parts means fewer bugs and less glue code. With a single, consistent interface for data and a clear one for schema, you can focus on what matters and ship what works.
How We Price
Transparent, predictable. One meter: records.
- Prices start at $49/mo.
- Choose a record bundle. One price, predictable every month.
- Records allow up to 50 fields and 20KB of data.
- When you hit your cap, you upgrade.
- Includes up to 10 environments
- Dedicated plans will be available later
Full pricing, which has four bundles, will be published when Beta launches so you can self-serve immediately.
Eager to ask a question?
Good — we expect it. Traverzer is a new kind of database, which means it’s totally normal to wonder “what the heck is this thing?”
Whether it’s a deep technical concern or just plain curiosity, we want to hear it. No jargon tests, no bad questions — just ask.
Build safer, faster
- ✓ Forget migrations. Schema evolves safely in the background.
- ✓ One endpoint. Insert, query, update, delete — all with JSON.
- ✓ Delete with confidence. Cascades prevent orphaned data by default.
- ✓ Any shape of data. Schema adapts as your data changes.
- ✓ Own your data. Export anytime, zero lock-in.
// Save (insert or update)
await put("https://tvzr.tech/data", JSON.stringify({
customer: { email: "alice@example.com", name: "Alice" }
}));
// Fetch
await post("https://tvzr.tech/data", JSON.stringify({
customer: {
fields: ["tvzr_key", "name", "email"],
where: { email: "alice@example.com" },
page: { first: 1 }
}
}));
// Delete
await delete("https://tvzr.tech/data", JSON.stringify({
customer:{
where: { email: "alice@example.com" }
},
tvzr_options: { confirmed: true, cascade: true }
}));await post("https://tvzr.tech/data", JSON.stringify({
customer: {
fields: ["name", "status", "country", "orders.total"],
where: {
$and: [
{ status: { $in: ["active", "trial"] } },
{ $or: [ { "orders.total": { $gte: 50 } },
{ country: { $in: ["US", "CA"] } } ] },
{ $not: { tier: "free" } }
]
},
page: { first: 25 }
}
}));Find exactly what you need
- ✓ Find what matters. Flexible filters across any model.
- ✓ Follow the links. Query relationships without joins or hacks.
- ✓ Paginate with ease. Built-in paging handles scale without boilerplate.
- ✓ Fast by design. No index tuning, no performance guesswork.
What a schema change feels like
Change a data type safely
automated migration
await put("/schema/fields/type",
JSON.stringify({
model: "order",
// total is a string
field: "total",
// change it to an int
to: "int",
// confirm the change
confirmed: true
})
);
// returns {change_id: "c_123..."}
// use to check status, cutover,
// cleanup, or rollbackConvert in the background
dual representation + read repair
// status sample
await get(
"/schema/changes/${id}/status"
);
// → {
// coverage: "99.2%",
// outliers: 3,
// eta: "3m"
// }Cut over or roll back
cooldown + cleanup
await post(
"/schema/changes/${id}/cutover"
);
// … later …
await post(
"/schema/changes/${id}/cleanup"
);
// drop old copy
// Done: all reads/writes use number
// rollback no longer available
// or
await post(
"/schema/changes/${id}/rollback"
);Your product evolves. Your database keeps up.
FAQ
Do I need to adopt a schema upfront?
No. Traverzer supports schema-on-ingest, so you can start by just sending JSON and let the system infer structure. But you’re not locked into that—at any time you can define models and fields explicitly through the schema API. Many teams start flexible and tighten later, mixing both approaches as their product matures.
How does Traverzer enforce safety?
Safety in Traverzer means your database keeps running smoothly even as the schema evolves. Schema changes are versioned and reconciled automatically, so you can add, rename, or retire fields without downtime or broken queries. Guardrails like type enforcement, aliasing, and soft deletes ensure that evolution happens in a controlled, production-safe way.
Is there lock-in?
We've designed Traverzer to make leaving just as straightforward as staying. Your data can always be exported as JSON, and your schema can be described via API. There are no proprietary query languages to unlearn. The goal is to earn trust through reliability, not to trap you in.
What stage is Traverzer in?
Traverzer is currently in pre-release. We're focused on validating reliability, finalizing the right feature set, and ensuring safety at scale. Public beta is planned for Q4 2025. In the meantime, we’re sharing updates through the changelog and building out the docs so early adopters know exactly what to expect.
Excited or unsure about Traverzer?
We'd love your support, hear your questions, or get you on the waitlist so you can try it for yourself.